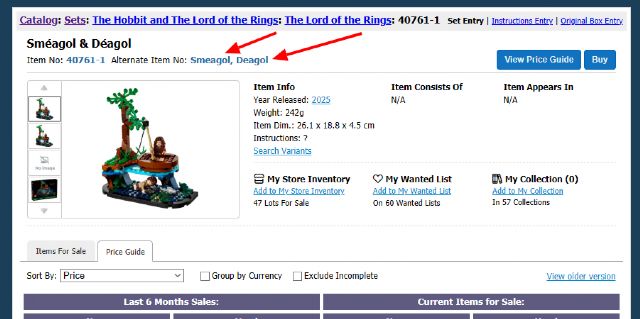
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
Now they need to do it for every other name with accented or similar characters.
Years ago I had Palantir added to the name of tghat part, but had similar requests
for German names in DFB rejected.
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
Now they need to do it for every other name with accented or similar characters.
Years ago I had Palantir added to the name of tghat part, but had similar requests
for German names in DFB rejected.
They are added like this to set names but for the likely hundreds of parts with
accents from various countries we are waiting for a proper solution for this
to be developed rather than using the above as a workaround.
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
Now they need to do it for every other name with accented or similar characters.
Years ago I had Palantir added to the name of tghat part, but had similar requests
for German names in DFB rejected.
They are added like this to set names but for the likely hundreds of parts with
accents from various countries we are waiting for a proper solution for this
to be developed rather than using the above as a workaround.
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
Now they need to do it for every other name with accented or similar characters.
Years ago I had Palantir added to the name of tghat part, but had similar requests
for German names in DFB rejected.
They are added like this to set names but for the likely hundreds of parts with
accents from various countries we are waiting for a proper solution for this
to be developed rather than using the above as a workaround.
Sméagol™ and Déagol™ are the English names….
Of course the "monster" must be French.
Nicely played Mr. Tolkien
Of course the "monster" must be French.
Nicely played Mr. Tolkien
That’s indeed an usual trend… but not this time! Tolkien was a philologist and
wanted to show how to correctly pronounce words.
Lots of words have diacriticts in his works.
The acute accent (é) and the diæresis (ë) are used to show the letter is pronounced
on its own:
— Sméagol = Sme-a-gol, not smee-gol
— Eärendil = E-a-rend-il, not ee-rend-il
— Óin = O-in, not… well, I don’t know how an English would pronounce Oin differently
🤔
And macron (ã) and circumflex (ê) show long vowels, etc.
But the (other) funny thing here is the ™: they are part of the official set
name
Of course the "monster" must be French.
Nicely played Mr. Tolkien
That’s indeed an usual trend… but not this time! Tolkien was a philologist and
wanted to show how to correctly pronounce words.
Lots of words have diacriticts in his works.
The acute accent (é) and the diæresis (ë) are used to show the letter is pronounced
on its own:
— Sméagol = Sme-a-gol, not smee-gol
— Eärendil = E-a-rend-il, not ee-rend-il
— Óin = O-in, not… well, I don’t know how an English would pronounce Oin differently
🤔
And macron (ã) and circumflex (ê) show long vowels, etc.
Ah, I was somewhat wrong (Appendix E in The Return of the King): the acute
accent is for long vowels, like the circumflex, it just depends on the language
(Eldar/Quenya use acute while Sindarin uses circumflex; in Dwarfish, circumflexes
are just for show).
But the (other) funny thing here is the ™: they are part of the official set
name
Of course the "monster" must be French.
Nicely played Mr. Tolkien
The funniest Easter egg is in the Appendices where Tolkien notes that the Orcs
(and some Dwarves) used a back or uvular 'r' "which the Eldar found
distasteful"
Of course the "monster" must be French.
Nicely played Mr. Tolkien
The funniest Easter egg is in the Appendices where Tolkien notes that the Orcs
(and some Dwarves) used a back or uvular 'r' "which the Eldar found
distasteful"
Aren't they the names in Westron rather than English, and not translated
to English unlike the rest if their speech.
Good point… except (proper) names generally aren’t translated, they are transliterated.
(Some locations are translated, like the Shire, Rivendell, or Bag End.)
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
I am not a fan of this solution because it can only be used one time. Alternate
item numbers are unique, so if any other item used these names, this workaround
is useless. Plus, they aren't alternate item numbers in any sense of the
meaning. The consistent way to do it for now is to include the alternate spellings
in the item name like all other sets that use characters with diacritics.
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
I am not a fan of this solution because it can only be used one time. Alternate
item numbers are unique, so if any other item used these names, this workaround
is useless. Plus, they aren't alternate item numbers in any sense of the
meaning. The consistent way to do it for now is to include the alternate spellings
in the item name like all other sets that use characters with diacritics.
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
The thing is, this should not be needed. Any *modern* search system should know
about NFD and NFKD. This is just sad...
For the mere mortals among us, the NxxD are about normalization of the characters
(Normalization Form: (K/compatiblity) Decomposition; K because there’s also NFC/NFKC
where C = Composition).
Roughly, those norms define how the “sub”characters (mostly accents for Latin
alphabets) are ordered and combined/separated… because Unicode allows to write
the same character in different ways: e_acute = e + acute.
Though, the terms aren’t really relevant to the issue of considering “é” and
“e” as equivalent when searching. Sure, N…D will allow you to see that e + acute
= e_acute are both the same letter, but, whatever normal form is used, “é” and
“e” are different.
It’s the choice of equivalence classes between characters that makes the search
successful or not, not whether the values are stored or compared in whatever
form.
The search fails on Rebrickable, but it works on Brickset and they don't
seem to have these as tags...
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
The thing is, this should not be needed. Any *modern* search system should know
about NFD and NFKD. This is just sad...
For the mere mortals among us, the NxxD are about normalization of the characters
(Normalization Form: (K/compatiblity) Decomposition; K because there’s also NFC/NFKC
where C = Composition).
Roughly, those norms define how the “sub”characters (mostly accents for Latin
alphabets) are ordered and combined/separated… because Unicode allows to write
the same character in different ways: e_acute = e + acute.
Though, the terms aren’t really relevant to the issue of considering “é” and
“e” as equivalent when searching. Sure, N…D will allow you to see that e + acute
= e_acute are both the same letter, but, whatever normal form is used, “é” and
“e” are different.
It’s the choice of equivalence classes between characters that makes the search
successful or not, not whether the values are stored or compared in whatever
form.
The search fails on Rebrickable, but it works on Brickset and they don't
seem to have these as tags...
My point was really that the mere mortals don't need to know this, but professionals
working on these systems really should...
As a professional, this topic would have me rolling my eyes but they already
got stuck on the "we have to reboot the database and shut down the website
once a day"-thing...
just saw this (image) and very much liked the makeshift tag system! for sure
going to help people find it!
The thing is, this should not be needed. Any *modern* search system should know
about NFD and NFKD. This is just sad...
For the mere mortals among us, the NxxD are about normalization of the characters
(Normalization Form: (K/compatiblity) Decomposition; K because there’s also NFC/NFKC
where C = Composition).
Roughly, those norms define how the “sub”characters (mostly accents for Latin
alphabets) are ordered and combined/separated… because Unicode allows to write
the same character in different ways: e_acute = e + acute.
Though, the terms aren’t really relevant to the issue of considering “é” and
“e” as equivalent when searching. Sure, N…D will allow you to see that e + acute
= e_acute are both the same letter, but, whatever normal form is used, “é” and
“e” are different.
It’s the choice of equivalence classes between characters that makes the search
successful or not, not whether the values are stored or compared in whatever
form.
The search fails on Rebrickable, but it works on Brickset and they don't
seem to have these as tags...
Yes, you understand the terms, but for their relevance in search you need to
do a little more research, like what about using \p{{Non_Spacing_Mark} next?